

インターネットで何かを調べるとき、多くの人が検索エンジンを利用しています。その検索エンジンの大部分を占めているのが「ロボット型検索エンジン」です。GoogleやBingなど、私たちが日常的に使っている検索サービスはすべてこのタイプに該当します。ロボット型検索エンジンは、クローラーと呼ばれるプログラムがWeb上の膨大な情報を自動収集し、データベース化することで検索結果を提供しています。WebサイトやWebマーケティングに携わる方にとって、この仕組みを理解することは非常に重要です。なぜなら、クローラーがどのようにWebページを評価しているかを知ることで、効果的なSEO対策が可能になるからです。この記事では、ロボット型検索エンジンの基本的な仕組みから、クローラーが重視するポイント、そして実践的な対策方法までをわかりやすく解説します。
- ロボット型検索エンジンの基本的な仕組みと特徴
クローラーによる自動巡回とインデックス登録により、膨大なWeb情報を効率的に検索できる仕組みになっています
- クローラーが重視する評価ポイント
コンテンツの品質、サイト構造、技術的要素など、複数の観点から総合的に評価されています
- 効果的なクローラー対策の実践方法
適切なサイト設計とコンテンツ最適化により、検索エンジンからの評価向上が期待できます
ロボット型検索エンジンの仕組み
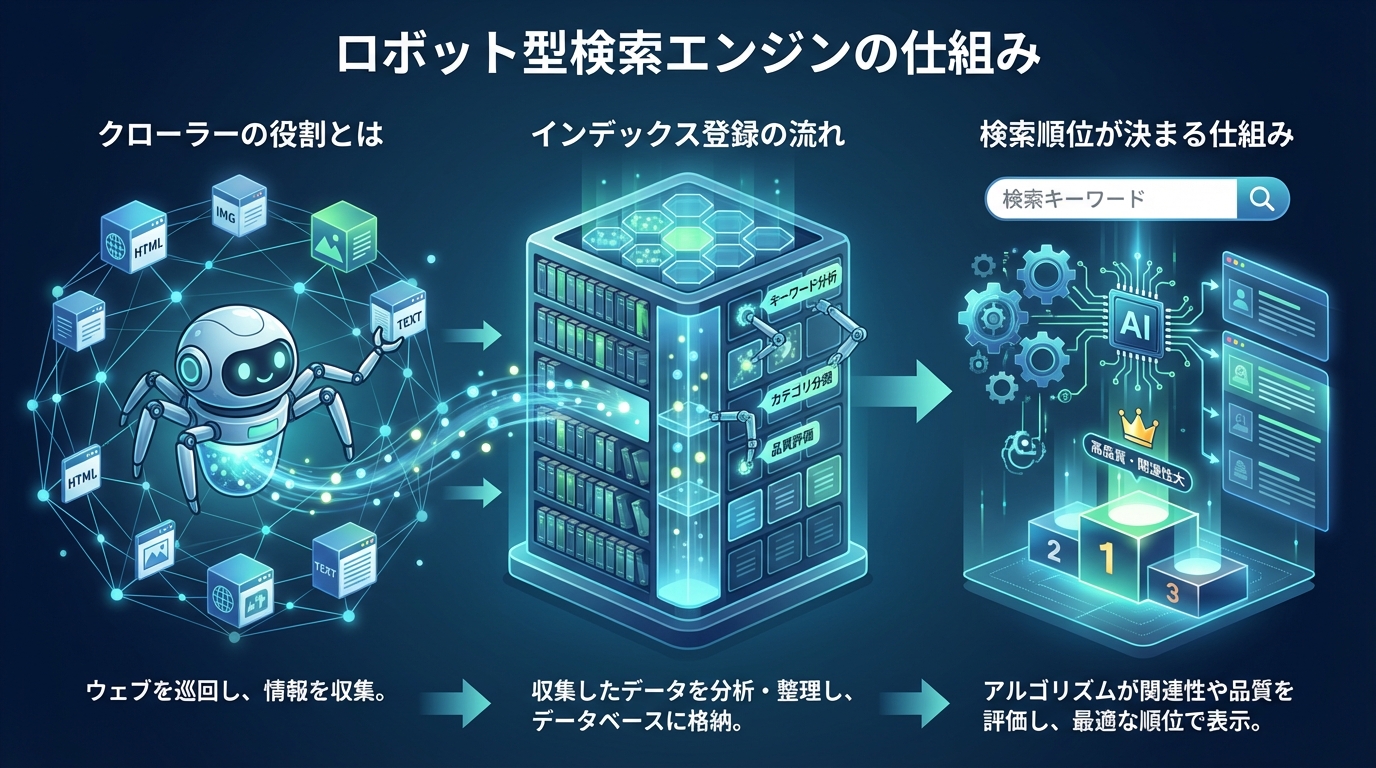
クローラーの役割とは
クローラーとは、Web上のページを自動的に巡回して情報を収集するプログラムのことです。「スパイダー」や「ボット」と呼ばれることもあります。クローラーはリンクをたどりながらWebサイトを移動し、ページの内容を読み取っていきます。
Googleの場合は「Googlebot」という名称のクローラーが使用されています。クローラーはテキスト情報だけでなく、画像や動画などのメディアファイル、PDFなどの文書ファイルの情報も収集対象としています。
インデックス登録の流れ
クローラーが収集した情報は、検索エンジンのデータベースに整理して保存されます。この保存作業を「インデックス登録」と呼び、登録されたページのみが検索結果に表示される仕組みになっています。
インデックス登録では、ページの内容が解析され、どのようなキーワードに関連するコンテンツなのかが判断されます。この段階で低品質と判断されたページは、インデックスに登録されない場合もあります。
検索順位が決まる仕組み
ユーザーが検索キーワードを入力すると、インデックスに登録されている膨大なページの中から関連性の高いものが抽出されます。そして、独自のアルゴリズムによって順位付けが行われ、検索結果として表示されます。
この順位付けには数百もの評価要素が関係しているとされており、コンテンツの品質や関連性、ユーザー体験などが総合的に判断されます。検索アルゴリズムは常に更新されており、より良い検索結果を提供するための改善が続けられています。
以下の表は、ロボット型検索エンジンの主要なプロセスをまとめたものです。
| プロセス | 内容 | 担当プログラム |
|---|---|---|
| クロール | Webページの自動巡回と情報収集 | クローラー |
| インデックス | 収集情報のデータベース登録 | インデクサー |
| ランキング | 検索結果の順位付けと表示 | 検索アルゴリズム |

クロール、インデックス、ランキングという3つのステップを理解することが、SEO対策の第一歩になります。

ロボット型検索エンジンの特徴
膨大な情報量を網羅できる
ロボット型検索エンジンの最大の強みは、Web上に存在する膨大な数のページを自動的に収集できる点です。人手による登録作業が不要なため、新しく公開されたページも比較的短期間で検索対象に含まれるようになります。
現在のインターネット上には数十億ものWebページが存在するとされています。これだけの情報を人手で管理することは現実的ではなく、自動化されたクローラーによる収集が不可欠となっています。
情報の鮮度を保てる
クローラーは定期的にWebサイトを巡回するため、ページの更新情報も検索結果に反映されやすくなっています。頻繁に更新されるサイトはクローラーの訪問頻度も高くなる傾向があり、最新の情報が検索結果に表示されやすくなります。
ニュースサイトやブログなど、日々新しいコンテンツが追加されるWebサイトでは、この特徴が特に重要になります。定期的な更新を続けることで、検索エンジンからの評価向上が期待できます。
検索精度の向上が続いている
検索アルゴリズムは常に改良が重ねられており、ユーザーの検索意図をより正確に理解できるようになっています。単純なキーワードマッチングだけでなく、文脈や意味を考慮した検索結果が提供されるようになりました。
近年では人工知能や機械学習の技術が活用され、ユーザーが本当に求めている情報を推測して表示する能力が大幅に向上しています。これにより、曖昧な検索キーワードでも適切な結果が得られるようになっています。
ロボット型検索エンジンとディレクトリ型検索エンジンの違いを以下の表にまとめました。
| 特徴 | ロボット型 | ディレクトリ型 |
|---|---|---|
| 情報収集方法 | クローラーによる自動収集 | 人手による登録 |
| 情報量 | 膨大 | 限定的 |
| 更新頻度 | 自動で随時更新 | 手動更新のため遅延 |
| 現在の主流 | 主流 | ほぼ廃止 |
ロボット型検索エンジンの主な特徴を確認しましょう。
- 自動収集により膨大なページを網羅
- 定期巡回で情報の鮮度を維持
- AIにより検索精度が向上
- 新規ページの迅速な反映が可能
自動化と継続的な精度向上が、ロボット型検索エンジンが主流となった理由です。
バクヤスAI 記事代行では、
高品質な記事を圧倒的なコストパフォーマンスでご提供!

クローラーが重視するポイント
コンテンツの質と関連性
クローラーが最も重視するのは、ユーザーにとって価値のある高品質なコンテンツであるかどうかです。単にキーワードを詰め込んだだけのページは評価されず、検索意図に応える充実した内容が求められます。
オリジナリティのある情報や、専門性の高い内容、そして正確で信頼性のある情報を提供することが大切です。他のサイトからのコピーコンテンツは低評価の対象となり、場合によってはインデックスから除外されることもあります。
サイト構造の最適化
クローラーがサイト内を効率よく巡回できるよう、適切なサイト構造を設計することが重要です。論理的な階層構造と、ページ間を結ぶ内部リンクの整備により、クローラーの巡回効率が向上します。
XMLサイトマップの設置も効果的な対策の一つです。サイトマップはサイト内のページ一覧をクローラーに伝える役割を果たし、新しいページや更新されたページを効率的にインデックスしてもらうことができます。
ページの読み込み速度
ページの表示速度は、クローラーの評価において重要な要素となっています。読み込みが遅いページはユーザー体験を損なうため、検索順位に悪影響を与える可能性があります。
画像の最適化、不要なスクリプトの削除、キャッシュの活用などにより、ページ速度を改善することが推奨されています。モバイル環境での表示速度も重要な評価対象となっています。
モバイル対応の重要性
現在の検索エンジンは、モバイルファーストインデックスを採用しています。これは、スマートフォンでの表示を基準にページを評価する仕組みです。
レスポンシブデザインの採用や、モバイルでの操作性向上により、検索エンジンからの評価を高めることができます。画面サイズに応じて適切に表示されるサイト設計が求められています。
クローラーが評価する主要なポイントを以下の表にまとめました。
| 評価カテゴリ | 主なポイント | 対策例 |
|---|---|---|
| コンテンツ | 品質・関連性・独自性 | ユーザー意図に応える記事作成 |
| 技術面 | サイト構造・表示速度 | サイトマップ設置・画像最適化 |
| ユーザー体験 | モバイル対応・操作性 | レスポンシブデザイン導入 |
コンテンツの質を高めつつ、技術面の最適化も忘れずに行うことが大切でしょう。
バクヤスAI 記事代行では、高品質な記事を圧倒的なコストパフォーマンスでご提供!
バクヤスAI 記事代行では、SEOの専門知識と豊富な実績を持つ専任担当者が、キーワード選定からAIを活用した記事作成、人の目による品質チェック、効果測定までワンストップでご支援いたします。
ご興味のある方は、ぜひ資料をダウンロードして詳細をご確認ください。
サービス導入事例

株式会社ヤマダデンキ 様
生成AIの活用により、以前よりも幅広いキーワードで、迅速にコンテンツ作成をすることが可能になりました。
親身になって相談に乗ってくれるTechSuiteさんにより、とても助かっております。
▶バクヤスAI 記事代行導入事例を見る

ロボット型検索エンジンへの対策方法
適切なキーワード設定
ターゲットとするキーワードを明確にし、タイトルや見出し、本文に自然な形で含めることが基本的な対策です。ただし、不自然なキーワードの詰め込みは逆効果となるため注意が必要です。
ユーザーがどのような言葉で検索するかを想像し、関連するキーワードや共起語も意識したコンテンツ作成が効果的です。キーワード調査ツールを活用することで、検索ボリュームや競合状況を把握することもできます。
メタタグの最適化
タイトルタグとメタディスクリプションは、検索結果に表示される重要な要素です。クローラーはこれらの情報を参考にページの内容を理解します。
タイトルには主要キーワードを含め、30文字程度で内容を的確に表現することが推奨されています。メタディスクリプションは検索結果のクリック率に影響するため、ユーザーの興味を引く文章を心がけましょう。
内部リンクの活用
サイト内のページ同士を適切にリンクで結ぶことで、クローラーの巡回効率が向上します。関連性の高いページへのリンクを設置することで、ユーザーの回遊率向上にもつながります。
アンカーテキストにはリンク先の内容を表すキーワードを含めることで、クローラーがページの関連性を理解しやすくなります。パンくずリストの設置も、サイト構造を明確にする効果的な方法です。
定期的なコンテンツ更新
クローラーは更新頻度の高いサイトを好む傾向があります。定期的に新しいコンテンツを追加したり、既存のコンテンツを最新情報に更新したりすることが重要です。
古くなった情報を放置せず、定期的にメンテナンスを行うことで、サイト全体の信頼性向上につながります。更新日を明記することも、ユーザーとクローラーの両方に対して効果的です。
ロボット型検索エンジン対策のチェックリストです。
- ターゲットキーワードを自然に配置
- タイトルタグとメタディスクリプションを最適化
- 内部リンクを適切に設置
- 定期的なコンテンツ更新を継続
- XMLサイトマップを設置・更新
基本的な対策を着実に積み重ねることが、長期的な成果につながりますよ。

クローラー制御の技術的手法
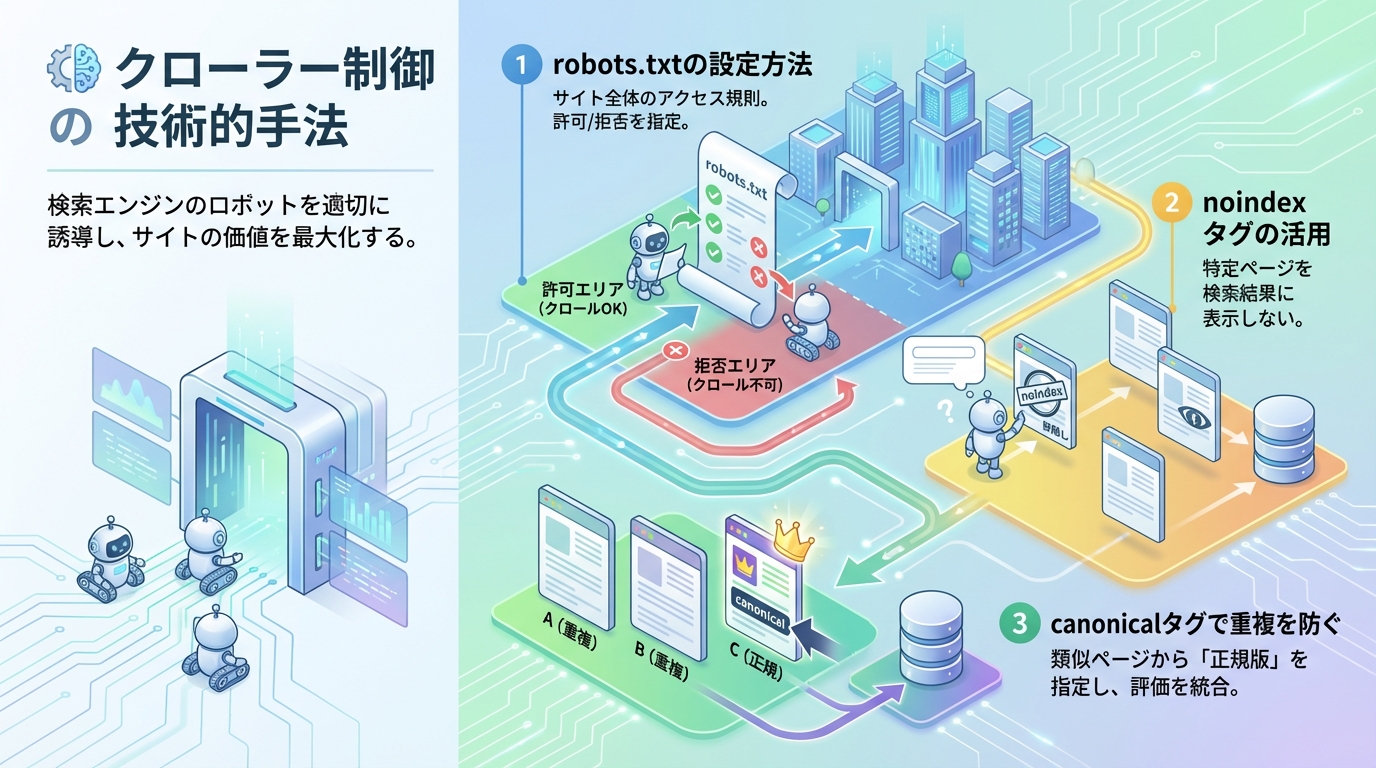
robots.txtの設定方法
robots.txtは、クローラーに対してサイト内のどのページを巡回してよいかを指示するためのファイルです。サイトのルートディレクトリに設置することで、クローラーはこのファイルを参照して巡回を行います。
管理画面や会員専用ページなど、検索結果に表示する必要のないページへのクロールを制限することで、クローラーのリソースを重要なページに集中させることができます。
noindexタグの活用
特定のページをインデックスさせたくない場合は、HTMLのheadセクションにnoindexタグを設置する方法があります。robots.txtとは異なり、ページ単位で細かく制御できる点が特徴です。
重複コンテンツや薄いコンテンツにnoindexを設定することで、サイト全体の品質評価を維持することができます。検索結果には表示させたくないが、サイト訪問者には見せたいページに適しています。
canonicalタグで重複を防ぐ
同じ内容のページが複数のURLで存在する場合、canonicalタグを使用して正規のURLを指定することが推奨されています。これにより、クローラーがどのURLを優先的にインデックスすべきかを理解できます。
パラメータ付きURLや、wwwの有無による重複など、意図せず発生する重複コンテンツ問題を解決する効果的な手段です。ECサイトなど、商品の絞り込み機能があるサイトでは特に重要な設定となります。
クローラー制御に使用する主な技術的手法を以下の表にまとめました。
| 手法 | 目的 | 設置場所 |
|---|---|---|
| robots.txt | クロールの許可・禁止 | サイトルートディレクトリ |
| noindexタグ | インデックス除外 | HTMLのheadセクション |
| canonicalタグ | 正規URL指定 | HTMLのheadセクション |
| XMLサイトマップ | クロール促進 | サイトルートディレクトリ |
クローラー制御を行う際の注意点を確認しましょう。
- 設定前に現状のインデックス状況を確認
- 変更後はSearch Consoleで動作確認
- 重要なページを誤ってブロックしない
- 定期的に設定内容を見直す
技術的な設定は慎重に行い、必ずテストを行ってから本番環境に適用しましょう。
よくある質問
- ロボット型検索エンジンとディレクトリ型検索エンジンの違いは何ですか
-
ロボット型検索エンジンはクローラーというプログラムが自動的にWeb上の情報を収集するのに対し、ディレクトリ型検索エンジンは人間が手作業でWebサイトを分類・登録します。現在はWeb上の情報量が膨大になったため、自動収集が可能なロボット型が主流となっており、ディレクトリ型はほぼ使用されなくなっています。
- 新しく作成したページがインデックスされるまでどのくらい時間がかかりますか
-
サイトの規模や更新頻度によって異なりますが、一般的には数日から数週間程度かかることが多いとされています。Google Search Consoleのインデックス登録リクエスト機能を使用することで、クローラーにページの存在を通知し、インデックスを促進することができます。ただし、リクエストしても必ずインデックスされるわけではありません。
- クローラーの巡回頻度を上げる方法はありますか
-
定期的に質の高いコンテンツを更新し続けることで、クローラーの訪問頻度が上がる傾向があります。また、XMLサイトマップを設置して最新の更新情報をクローラーに伝えることも効果的です。サイトの表示速度を改善し、クロールしやすい環境を整えることも重要です。
- robots.txtで全ページをブロックしてしまった場合どうなりますか
-
robots.txtで全ページへのクロールをブロックすると、クローラーがサイトの内容を収集できなくなり、検索結果からページが徐々に消えていく可能性があります。誤って設定してしまった場合は、すぐにrobots.txtを修正し、Google Search Consoleで再クロールをリクエストすることが推奨されます。

まとめ
ロボット型検索エンジンは、クローラーによる自動巡回、インデックス登録、ランキングという3つのプロセスで動作しています。この仕組みを理解することが、効果的なSEO対策の基盤となります。
クローラーが重視するポイントは、コンテンツの品質、サイト構造の最適化、ページ速度、そしてモバイル対応など多岐にわたります。これらをバランスよく改善していくことで、検索結果での表示順位向上が期待できます。
技術的なクローラー制御も重要ですが、最も大切なのはユーザーにとって価値のあるコンテンツを継続的に提供することです。検索エンジンの最終目標はユーザーに最適な情報を届けることであり、その点を意識したサイト運営を心がけましょう。
