


ChatGPTやGeminiなど、AIが画像や音声を理解して回答する場面を目にする機会が増えてきました。これらのAIに共通する技術が「マルチモーダルAI」です。従来のAIはテキストのみを処理するものが主流でしたが、マルチモーダルAIは画像、音声、動画など複数の情報を同時に処理できます。この技術により、AIはより人間に近い形で情報を理解し、応答することが可能になりました。本記事では、マルチモーダルAIの基本的な仕組みから、ビジネスでの活用事例、そして現在抱えている課題まで、専門知識がなくても理解できるようわかりやすく解説します。
- マルチモーダルAIの基本的な仕組みと従来AIとの違い
マルチモーダルAIは複数の情報形式を統合処理することで、人間の認知に近い理解を実現しています
- ビジネス分野での具体的な活用シーン
医療、製造業、カスタマーサポートなど幅広い業界で業務効率化や新サービス創出に貢献しています
- 導入時に注意すべき課題と今後の展望
計算コストやプライバシー問題などの課題を理解した上で、段階的な導入計画を立てることが重要です
マルチモーダルAIとは
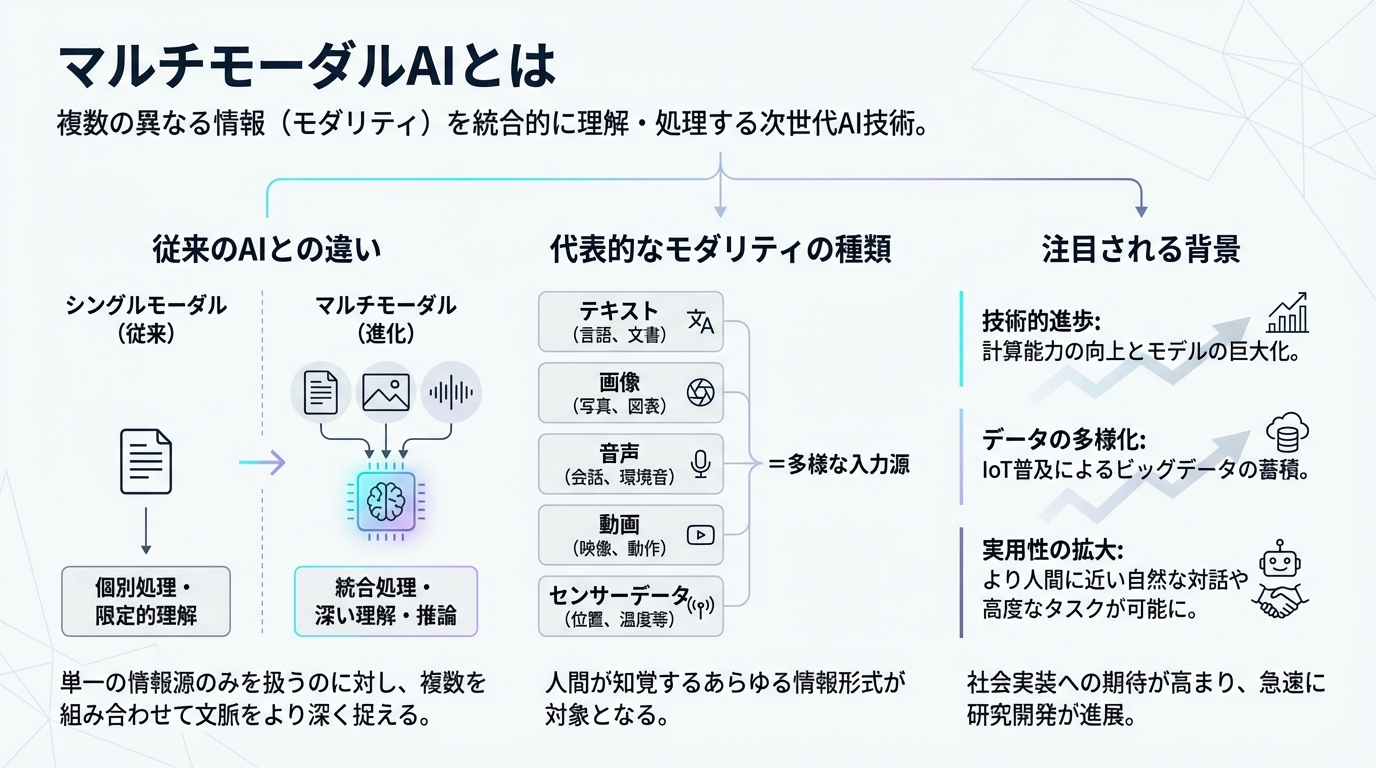
従来のAIとの違い
従来のAIは「シングルモーダル」と呼ばれ、テキストならテキスト、画像なら画像というように、単一の情報形式のみを処理していました。たとえば、文章生成AIはテキストのみを扱い、画像認識AIは画像のみを分析するという形です。
これに対してマルチモーダルAIは、画像を見ながらその内容を説明したり、音声を聞きながら適切なテキスト応答を生成したりすることが可能です。この統合的な処理能力により、より文脈に即した高精度な応答が実現しています。
| 項目 | シングルモーダルAI | マルチモーダルAI |
|---|---|---|
| 処理可能なデータ | 単一形式のみ | 複数形式を同時処理 |
| 情報の理解度 | 限定的 | 文脈を考慮した包括的理解 |
| 応用範囲 | 特定タスクに特化 | 幅広い分野に対応 |
代表的なモダリティの種類
マルチモーダルAIが扱う主なモダリティには、テキスト、画像、音声、動画、センサーデータなどがあります。これらの情報を組み合わせることで、単一のデータからは得られない深い洞察や正確な判断が可能になります。
たとえば、防犯カメラの映像と音声を組み合わせることで、異常事態の検知精度が向上します。また、医療分野では、画像診断と患者の症状記録を統合することで、より精度の高い診断支援が実現しています。
注目される背景
マルチモーダルAIが注目される背景には、ディープラーニング技術の進歩と計算能力の向上があります。特に「Transformer」と呼ばれる技術の登場により、異なる種類のデータを効率的に統合処理できるようになりました。
GPT-4やGeminiなどの大規模言語モデルがマルチモーダル機能を搭載したことで、一般ユーザーにも広く利用されるようになっています。この技術革新により、AIの活用範囲は飛躍的に拡大しました。

マルチモーダルAIは複数の情報を同時に処理できるため、人間の認知により近い理解が可能です。従来のAIとは一線を画す技術と言えるでしょう。

マルチモーダルAIの仕組み
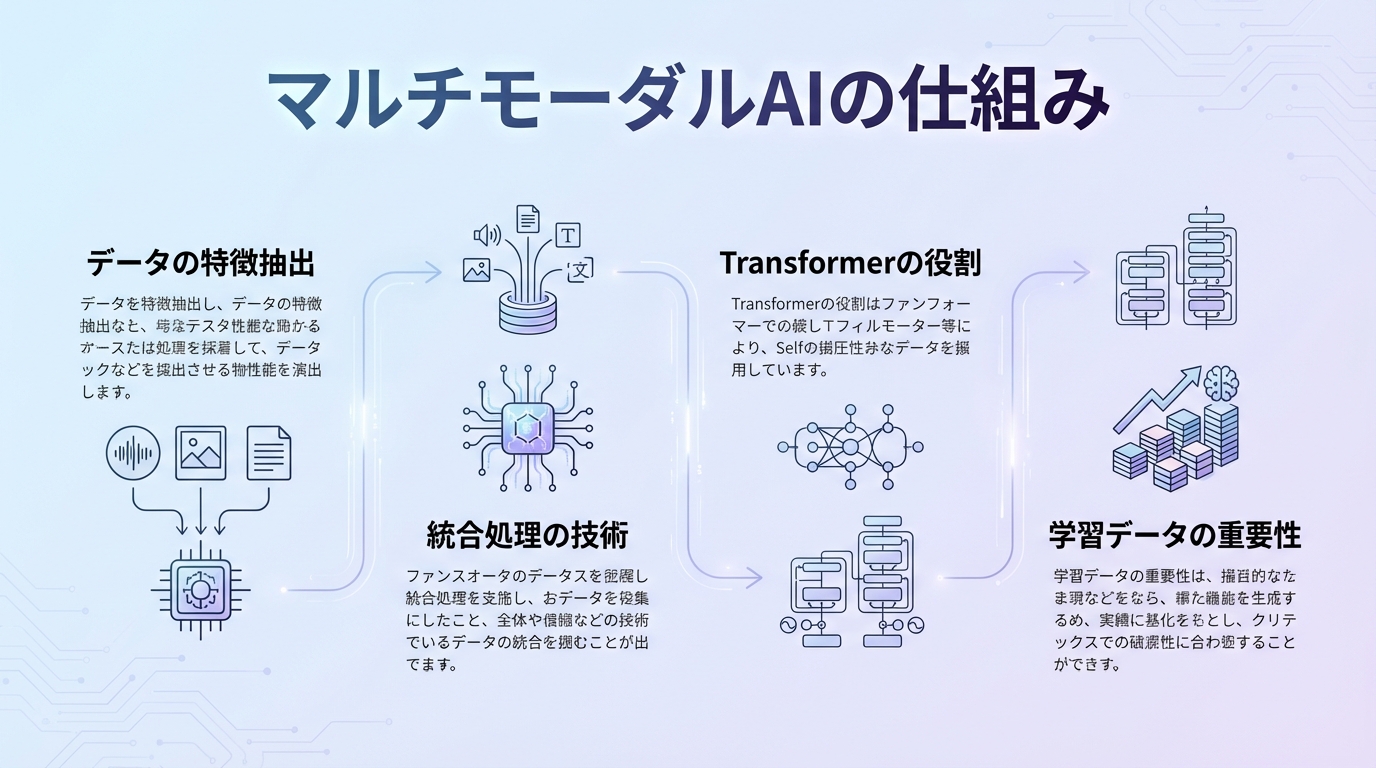
データの特徴抽出
マルチモーダルAIの第一段階は、各モダリティからの特徴抽出です。画像であれば形や色、テクスチャなどの視覚的特徴を、音声であれば周波数やリズムなどの音響的特徴を抽出します。
この特徴抽出には、畳み込みニューラルネットワーク(CNN)や再帰型ニューラルネットワーク(RNN)などの深層学習モデルが使用されています。各モダリティに特化したモデルが、それぞれのデータから重要な情報を取り出す役割を担っています。
統合処理の技術
抽出された特徴は、統合処理によって一つの表現空間にまとめられます。この過程では「アテンション機構」と呼ばれる技術が重要な役割を果たしています。
アテンション機構により、異なるモダリティ間の関連性を学習し、どの情報に注目すべきかを自動的に判断できるようになります。たとえば、画像とテキストを処理する際、画像のどの部分がテキストのどの単語と関連しているかを把握することが可能です。
マルチモーダルAIの統合処理における重要ポイント
- 各モダリティの特徴を共通の表現空間に変換
- アテンション機構による関連性の学習
- 文脈を考慮した情報の重み付け
- 最終的な出力のための統合判断
Transformerの役割
現在のマルチモーダルAIの多くは、Transformerアーキテクチャをベースにしています。Transformerは元々自然言語処理のために開発されましたが、その汎用性の高さから、画像や音声の処理にも応用されるようになりました。
Vision Transformer(ViT)は画像をパッチに分割して処理する手法で、画像認識の精度を大幅に向上させました。このような技術の発展により、異なるモダリティを統一的なフレームワークで処理することが可能になっています。
| 技術要素 | 役割 | 特徴 |
|---|---|---|
| CNN | 画像特徴抽出 | 空間的なパターン認識に優れる |
| RNN/LSTM | 時系列データ処理 | 音声や動画の時間的変化を捉える |
| Transformer | 統合処理 | 長距離の依存関係を効率的に学習 |
| アテンション機構 | 関連性学習 | 重要な情報への注目を自動調整 |
学習データの重要性
マルチモーダルAIの性能は、学習に使用するデータの質と量に大きく依存します。画像とテキストのペアデータ、動画と音声の同期データなど、適切に対応付けられた大量のデータが必要となります。
近年では、インターネット上の大規模なデータセットを活用した事前学習が一般的になっています。この事前学習により、特定のタスクに対して少量のデータで高い性能を発揮できるようになりました。
マルチモーダルAIの仕組みは複雑ですが、特徴抽出と統合処理という2段階で理解すると把握しやすくなります。Transformer技術の発展が大きな転換点となりました。
バクヤスAI 記事代行では、
高品質な記事を圧倒的なコストパフォーマンスでご提供!
マルチモーダルAIのビジネス活用
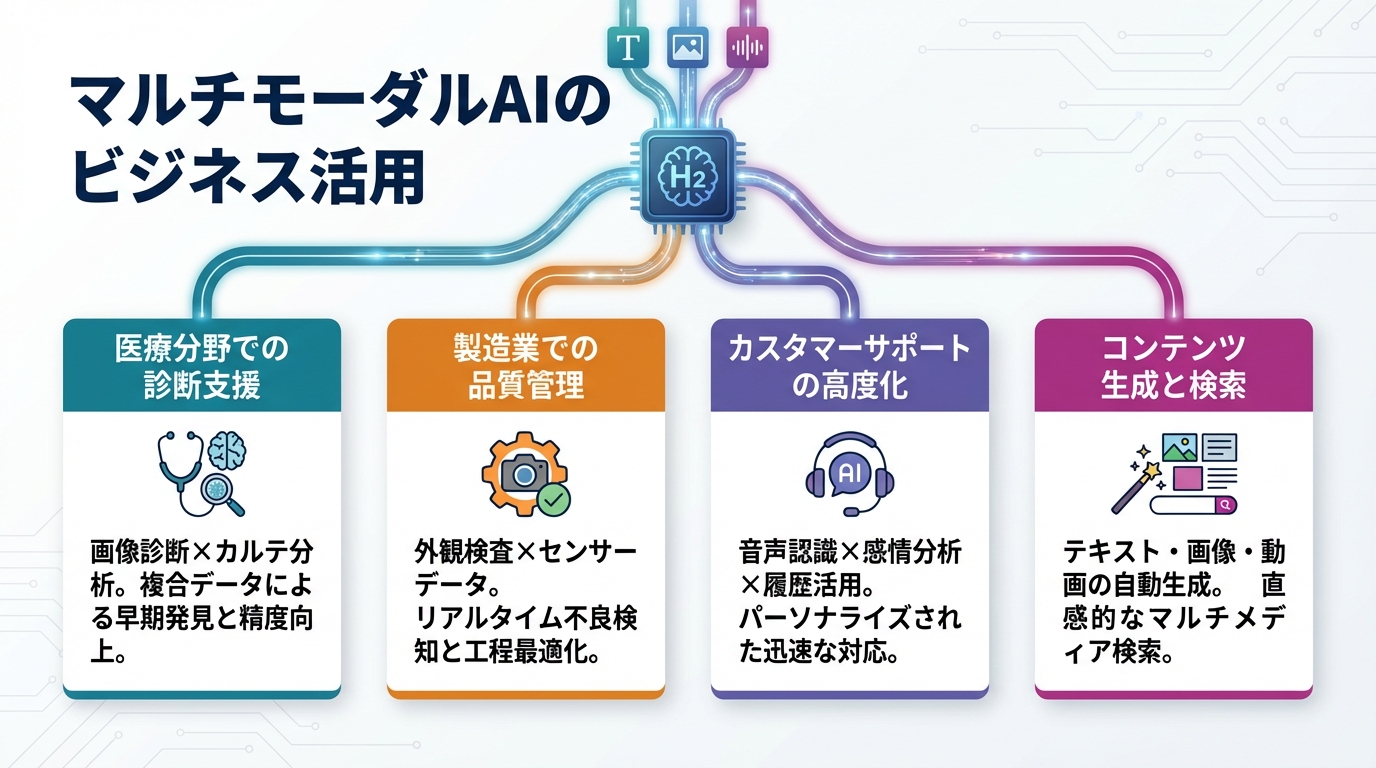
医療分野での診断支援
医療分野では、マルチモーダルAIが診断支援に活用されています。X線画像やCTスキャンなどの医用画像と、患者の症状記録や検査数値を組み合わせることで、より精度の高い診断支援が可能になります。
画像診断だけでは見落とす可能性のある異常も、患者の臨床データと組み合わせることで検出精度が向上すると考えられています。特に、がんの早期発見や希少疾患の診断において、その効果が期待されています。
製造業での品質管理
製造業では、カメラ画像とセンサーデータを組み合わせた品質管理にマルチモーダルAIが活用されています。製品の外観検査だけでなく、温度や振動などのセンサー情報を統合することで、不良品の検出精度が向上します。
従来の画像検査では検出が困難だった内部欠陥も、複数のセンサー情報を組み合わせることで発見できる可能性が高まっています。これにより、出荷前の品質保証が強化されています。
| 活用分野 | 使用するモダリティ | 期待される効果 |
|---|---|---|
| 医療診断 | 画像、テキスト、数値データ | 診断精度の向上、早期発見 |
| 品質管理 | 画像、センサーデータ | 不良品検出率の向上 |
| カスタマーサポート | テキスト、音声、画像 | 対応時間の短縮、満足度向上 |
| 小売・マーケティング | 画像、テキスト、行動データ | パーソナライズ精度の向上 |
カスタマーサポートの高度化
カスタマーサポートでは、顧客からの問い合わせ内容(テキスト)、添付された画像、通話音声などを統合的に分析することで、より適切な回答を提供できるようになっています。
たとえば、製品の不具合に関する問い合わせでは、顧客が送付した写真を分析しながら、テキストでの状況説明を理解し、最適な解決策を提案することが可能です。この統合的なアプローチにより、問題解決までの時間短縮と顧客満足度の向上が期待できます。
マルチモーダルAI導入を検討する際のチェックポイント
- 自社の業務で複数の情報形式を扱う場面があるか
- 現状の単一モダリティ処理で課題を感じているか
- 統合処理により得られるメリットが明確か
- 必要なデータの収集・整備が可能か
コンテンツ生成と検索
マーケティングやコンテンツ制作の分野では、画像とテキストを組み合わせたコンテンツ生成が注目されています。商品画像から自動的に説明文を生成したり、テキストの指示に基づいて画像を生成したりする応用が広がっています。
また、検索システムにおいても、画像とテキストを組み合わせた検索が可能になっています。言葉だけでは表現しにくい検索意図も、画像を併用することでより正確に伝えられるようになりました。
マルチモーダルAIのビジネス活用は多岐にわたります。自社の業務にどう適用できるか、具体的なユースケースを検討してみましょう。
バクヤスAI 記事代行では、高品質な記事を圧倒的なコストパフォーマンスでご提供!
バクヤスAI 記事代行では、SEOの専門知識と豊富な実績を持つ専任担当者が、キーワード選定からAIを活用した記事作成、人の目による品質チェック、効果測定までワンストップでご支援いたします。
ご興味のある方は、ぜひ資料をダウンロードして詳細をご確認ください。
サービス導入事例

株式会社ヤマダデンキ 様
生成AIの活用により、以前よりも幅広いキーワードで、迅速にコンテンツ作成をすることが可能になりました。
親身になって相談に乗ってくれるTechSuiteさんにより、とても助かっております。
▶バクヤスAI 記事代行導入事例を見る
マルチモーダルAIの課題
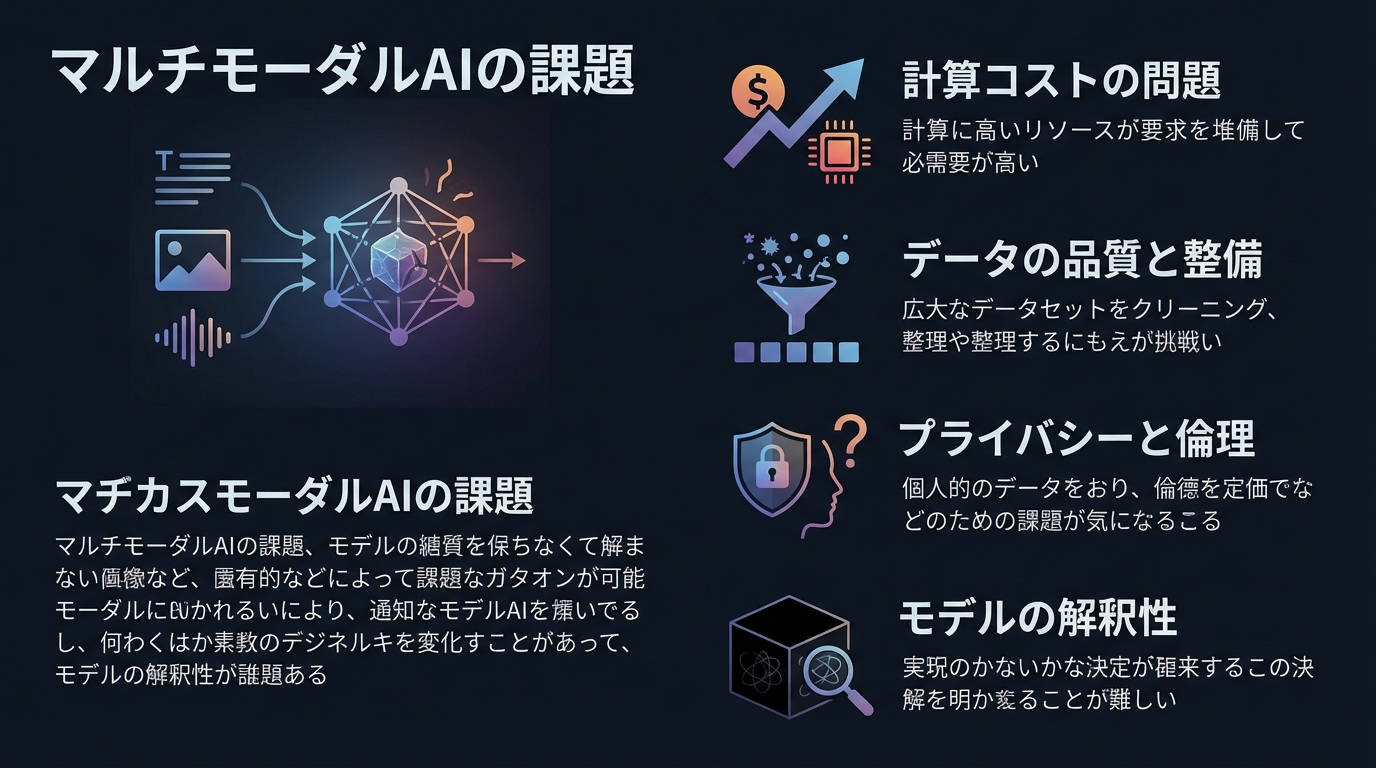
計算コストの問題
マルチモーダルAIは複数のデータを同時に処理するため、シングルモーダルAIと比較して計算コストが高くなります。大量の画像や動画を処理する場合、高性能なGPUやクラウドリソースが必要となり、運用コストが増加します。
特にリアルタイム処理が求められる用途では、処理速度と精度のバランスを取ることが重要な課題となっています。エッジデバイスでの処理を可能にするための軽量化技術の研究も進められています。
データの品質と整備
マルチモーダルAIの学習には、異なるモダリティ間で適切に対応付けられたデータが必要です。しかし、このような高品質なデータセットの構築には多大な労力とコストがかかります。
特に専門分野のデータは、アノテーション(ラベル付け)に専門知識が必要となり、データ整備のハードルが高くなりがちです。医療分野などでは、プライバシーの観点からデータ収集自体が困難なケースもあります。
| 課題カテゴリ | 具体的な問題 | 対応策の方向性 |
|---|---|---|
| 計算コスト | 高いリソース要求 | モデルの軽量化、効率化 |
| データ | 品質・量の確保 | 合成データ活用、転移学習 |
| プライバシー | 個人情報の保護 | 匿名化技術、オンデバイス処理 |
| 解釈性 | 判断根拠の不透明さ | 説明可能AI技術の導入 |
プライバシーと倫理
画像や音声を処理するマルチモーダルAIは、個人を特定できる情報を扱う機会が多くなります。顔認識や音声認識は便利な技術である一方、プライバシー侵害のリスクも伴います。
また、学習データに含まれるバイアスが、AIの判断に影響を与える可能性も指摘されています。公平で偏りのないAIを実現するためには、データ収集段階からの配慮と、継続的なモニタリングが必要です。
マルチモーダルAI導入時のリスク管理チェックリスト
- 個人情報保護の方針と手順が明確か
- 学習データのバイアス評価を実施しているか
- AIの判断に対する説明責任を果たせるか
- 定期的な性能モニタリング体制があるか
モデルの解釈性
マルチモーダルAIは複数の情報を統合して判断を行うため、その判断根拠を人間が理解することが難しくなります。特に医療や金融など、説明責任が求められる分野では、この「ブラックボックス性」が導入の障壁となることがあります。
この課題に対しては、説明可能AI(Explainable AI)の研究が進められています。どの情報がどの程度判断に影響したかを可視化する技術により、AIの意思決定プロセスの透明性向上が図られています。
課題を把握した上で導入を進めることが成功の鍵です。特にプライバシーと説明責任については、事前に十分な検討が必要でしょう。
マルチモーダルAIの今後
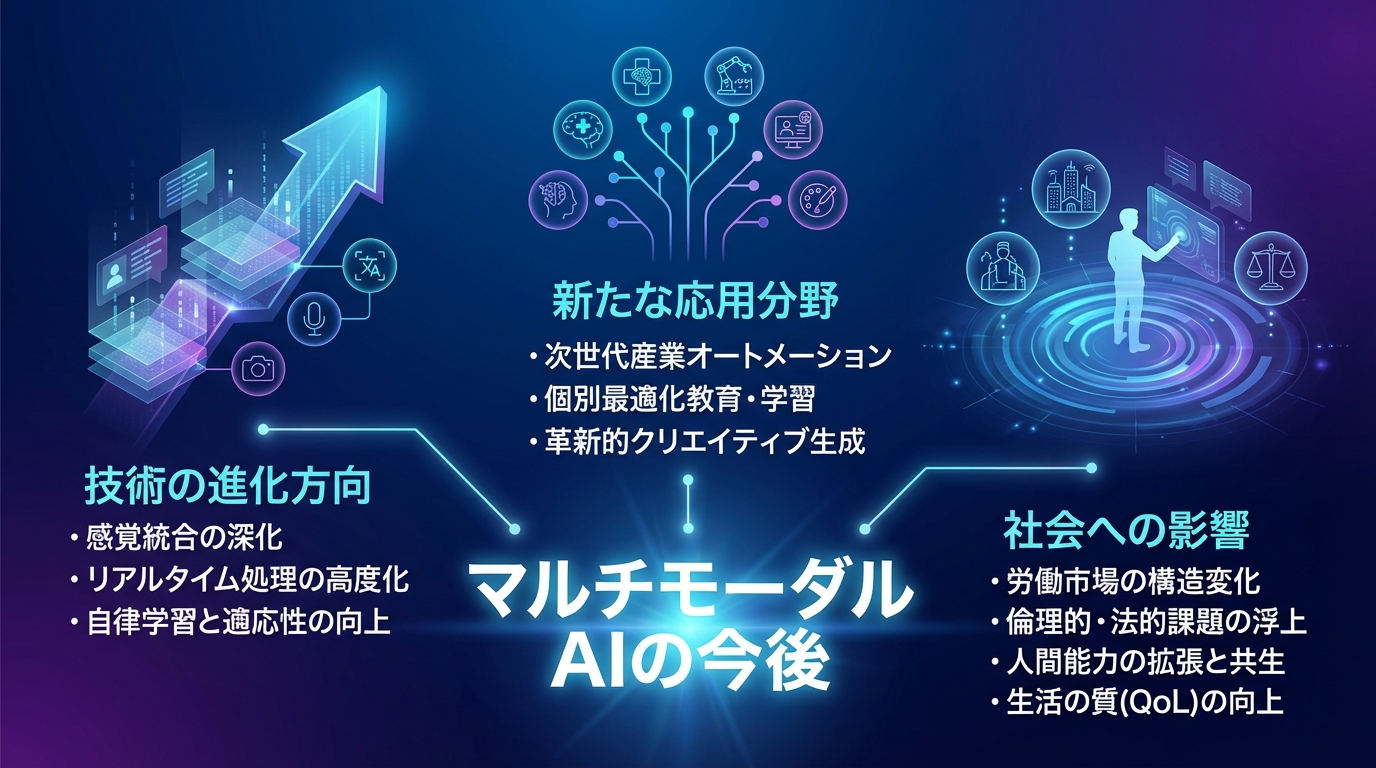
技術の進化方向
マルチモーダルAIの技術は、より多くのモダリティを統合する方向に進化しています。現在は主にテキスト、画像、音声が中心ですが、触覚情報や嗅覚情報など、より多様なセンサーデータとの統合も研究されています。
また、モデルの効率化も重要な研究テーマとなっており、スマートフォンなどのエッジデバイスでも動作する軽量なマルチモーダルAIの開発が進められています。これにより、クラウドに依存しない、プライバシーに配慮したAI活用が可能になると考えられています。
新たな応用分野
マルチモーダルAIの応用分野は拡大を続けています。自動運転では、カメラ映像、LiDARデータ、地図情報などを統合した高度な環境認識が実現しつつあります。ロボティクス分野では、視覚と触覚を組み合わせた繊細な作業の自動化が研究されています。
教育分野では、学習者の表情や音声から理解度を推定し、個別最適化された学習支援を提供するシステムの開発も進んでいます。このように、人間とAIのインタラクションがより自然で豊かになることが期待されています。
社会への影響
マルチモーダルAIの普及は、社会に大きな変化をもたらす可能性があります。業務の自動化による生産性向上が期待される一方で、雇用への影響も議論されています。
また、AIが人間とより自然にコミュニケーションできるようになることで、高齢者や障がいを持つ方々のサポートにも活用されることが期待されています。技術の発展とともに、その恩恵を社会全体で享受できる仕組みづくりが重要となります。
マルチモーダルAIの進化はまだ始まったばかりです。技術動向を継続的にウォッチしながら、自社への適用タイミングを見極めていきましょう。
よくある質問
- マルチモーダルAIと生成AIの違いは何ですか
-
生成AIはテキストや画像などのコンテンツを新たに生成する能力を持つAIを指します。一方、マルチモーダルAIは複数の情報形式を同時に処理できるAIを指します。両者は排他的ではなく、GPT-4のように生成能力とマルチモーダル能力の両方を持つAIも存在します。
- マルチモーダルAIの導入にはどのくらいのコストがかかりますか
-
導入コストは用途や規模によって大きく異なります。クラウドサービスのAPIを利用する場合は比較的低コストで始められますが、自社専用のモデルを構築する場合は、データ整備やインフラ構築に相応の投資が必要となります。まずは既存のAPIサービスで効果を検証してから本格導入を検討することが一般的です。
- マルチモーダルAIは中小企業でも活用できますか
-
活用可能です。近年はGPT-4やGeminiなどの大手サービスがAPIを提供しており、自社でAIを開発する必要なく、マルチモーダルAIの機能を利用できます。カスタマーサポートの効率化や商品画像からの説明文生成など、比較的導入しやすい用途から始めることが考えられます。
- マルチモーダルAIの精度はどの程度信頼できますか
-
精度はタスクや使用するモデルによって異なります。一般的な用途では高い精度を発揮しますが、専門分野や複雑な判断が必要な場面では、人間による確認が必要な場合もあります。医療診断など重要な判断に使用する際は、あくまで支援ツールとして位置づけ、最終判断は専門家が行う運用が推奨されています。
まとめ
マルチモーダルAIは、テキスト、画像、音声など複数の情報形式を同時に処理できる技術です。この能力により、人間の認知に近い形での情報理解が可能となり、さまざまな分野での活用が広がっています。
医療診断支援、製造業の品質管理、カスタマーサポートの高度化など、すでに多くの業界で実用化が進んでいます。一方で、計算コスト、データ品質、プライバシー、モデルの解釈性といった課題も存在し、これらへの対応が今後の普及において重要となります。
マルチモーダルAIの技術は急速に進化しており、今後さらに多様な応用が期待されています。自社のビジネスにおける活用可能性を検討する際は、まず小規模な実証実験から始め、効果を確認しながら段階的に導入を進めることが有効な選択肢となるでしょう。