


近年、AI技術の急速な発展に伴い「AIクローラー」という言葉を耳にする機会が増えています。AIクローラーとは、AI学習用のデータを収集するためにWebサイトを巡回するプログラムのことです。従来の検索エンジン向けクローラーとは異なり、大量のコンテンツを学習データとして取得する点が特徴で、サイト運営者にとっては新たな課題となっています。本記事では、AIクローラーの基本的な仕組みから、代表的な種類、サーバーへの影響、そして具体的なブロック方法まで幅広く解説します。自社サイトを適切に守るための知識として、ぜひ最後までお読みください。
- AIクローラーの仕組みと従来のクローラーとの違い
AIクローラーはAIモデルの学習データを収集する目的で動作し、検索エンジンのクローラーとはアクセス頻度や取得するデータ量が大きく異なります。
- 代表的なAIクローラーの種類と特徴
GPTBot、ClaudeBot、Google-Extendedなど、各AI開発元が独自のクローラーを運用しており、それぞれ挙動やポリシーが異なります。
- AIクローラーの具体的なブロック方法
robots.txtの設定やメタタグの活用など、サイト運営者が実践できる複数の対策方法があります。
AIクローラーの基本的な仕組み
AIクローラーの動作原理
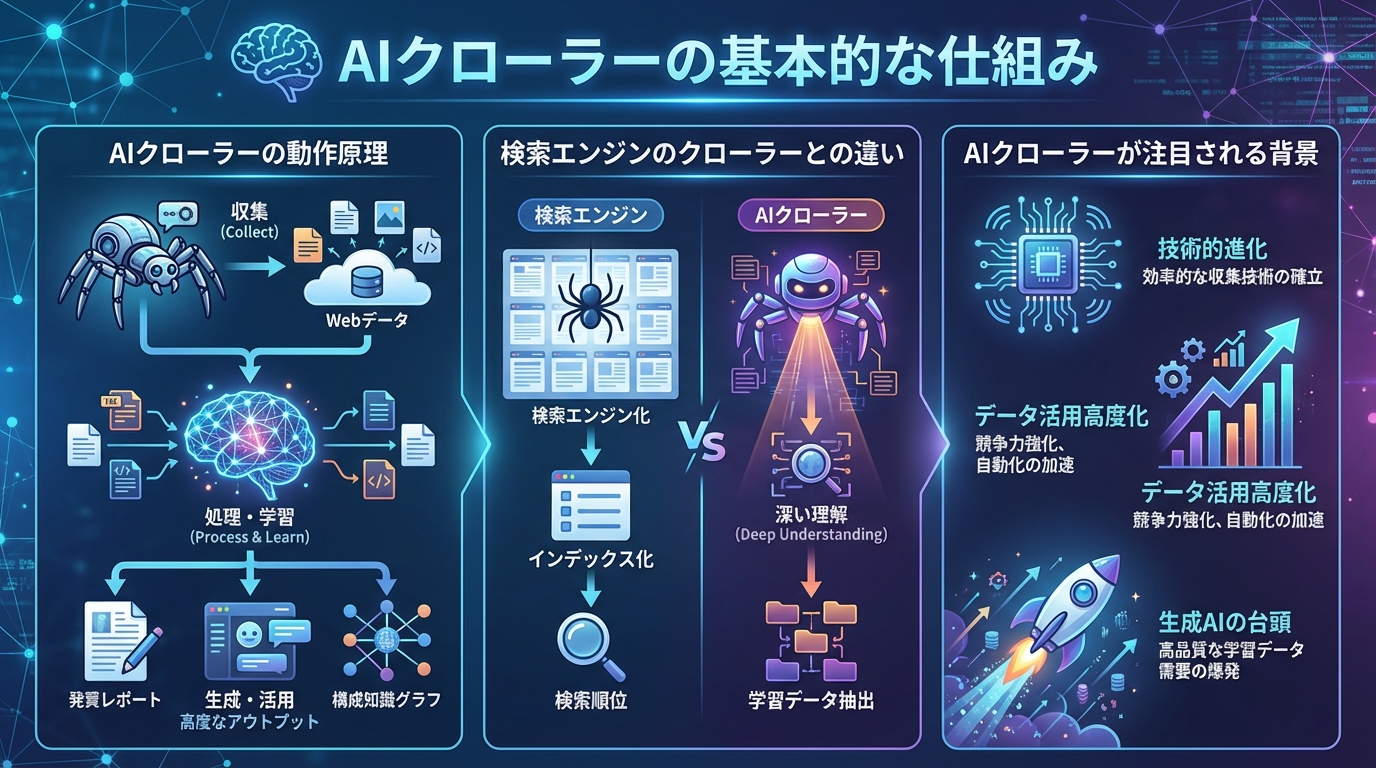
AIクローラーは、Webページ上のテキスト・画像・リンク構造などを自動的に取得し、AI学習用のデータセットとして蓄積する仕組みで動作します。具体的には、あるURLにアクセスしてHTMLを解析し、ページ内のコンテンツを取得したうえで、リンク先のページへと次々に移動していきます。
このプロセスは24時間体制で行われることが多く、短時間で膨大な数のページにアクセスするケースも見られます。取得されたデータはAIモデルのトレーニングに使用され、文章生成や質問応答といった機能の精度向上に役立てられています。
検索エンジンのクローラーとの違い
AIクローラーと検索エンジンのクローラー(例えばGooglebot)は、動作の仕組みこそ似ていますが、目的とアクセスの性質が大きく異なります。以下の表で主な違いを整理します。
| 比較項目 | 検索エンジンのクローラー | AIクローラー |
|---|---|---|
| 主な目的 | 検索インデックスの作成 | AI学習データの収集 |
| サイトへの還元 | 検索結果に表示されトラフィックが増える | 直接的な還元は限定的 |
| アクセス頻度 | サイトの重要度に応じて調整 | 大量・高頻度になりやすい |
| robots.txtの遵守 | 原則として遵守 | 遵守する場合もあるが統一されていない |
検索エンジンのクローラーはサイトにトラフィックを還元する一方、AIクローラーは学習データとしてコンテンツを利用するため、サイト運営者にとっては直接的なメリットが得にくいという違いがあります。この点が、AIクローラーに対して懸念が広がっている大きな理由の一つです。
AIクローラーが注目される背景
AIクローラーが注目を集めるようになった背景には、生成AIの急速な普及があります。大規模言語モデル(LLM)と呼ばれるAIは、膨大なテキストデータで学習することで高い精度を実現しており、その学習データの確保が重要な課題となっています。
一方で、AIクローラーによる大量アクセスがサーバーに負荷をかけたり、著作権のあるコンテンツが無断で学習に使われたりするリスクも指摘されています。こうした問題意識の高まりから、AIクローラーへの対策は多くのサイト運営者にとって優先度の高いテーマとなっています。

AIクローラーは検索エンジンのクローラーとは目的が異なるため、対策も別に考える必要があるでしょう。

代表的なAIクローラーの種類
主要なAIクローラーの一覧
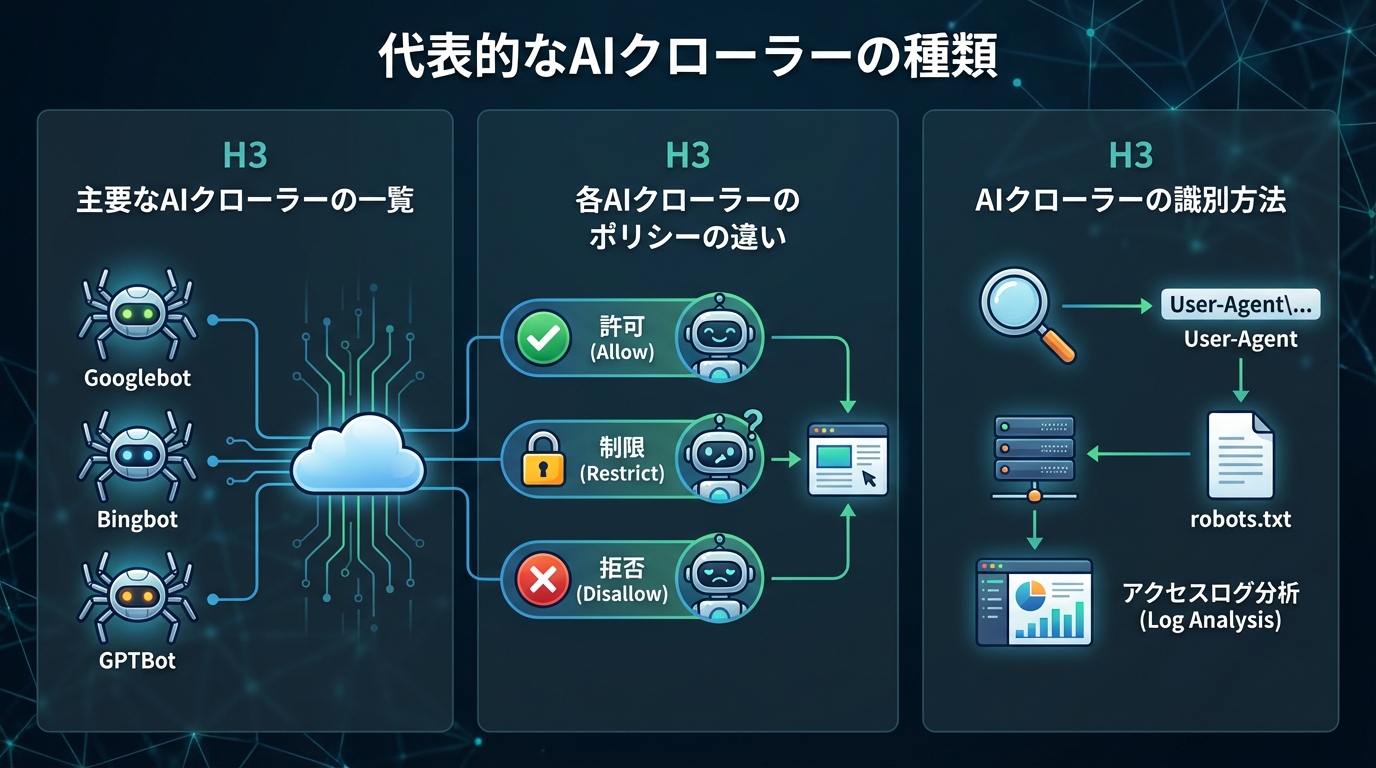
以下に、代表的なAIクローラーとその運営元、主な用途を表にまとめました。
| AIクローラー名 | 運営元 | 主な用途 |
|---|---|---|
| GPTBot | OpenAI | GPTシリーズの学習データ収集 |
| ClaudeBot | Anthropic | Claudeモデルの学習データ収集 |
| Google-Extended | Geminiなど生成AI向けデータ収集 | |
| CCBot | Common Crawl | オープンなWebデータセット構築 |
| Bytespider | ByteDance | AI関連サービスのデータ収集 |
AIクローラーはそれぞれ運営元や利用目的が異なるため、ブロック対象を選定する際には個別に確認する必要があります。特にGPTBotやClaudeBotは、robots.txtによるブロック指示に対応していることが公表されています。
各AIクローラーのポリシーの違い
AIクローラーごとに、robots.txtへの対応方針には差があります。OpenAIのGPTBotやAnthropicのClaudeBotは、サイト運営者がrobots.txtでアクセス拒否を設定した場合にそれを尊重すると公表しています。
一方で、すべてのAIクローラーがrobots.txtを遵守するとは限らない点にも注意が必要です。AIクローラーの対応ポリシーは開発元によって異なり、今後も変更される可能性があるため、定期的に最新情報を確認することが重要です。
AIクローラーの識別方法
サーバーのアクセスログを確認することで、どのAIクローラーが自サイトにアクセスしているかを把握できます。ログに記録されるUser-Agent文字列を確認し、GPTBotやClaudeBotといった名称が含まれていれば、AIクローラーによるアクセスと判別できます。
アクセスログの確認が難しい場合は、サーバー管理ツールやアクセス解析ツールを活用する方法もあります。まずは自サイトへのAIクローラーのアクセス状況を把握することが、適切な対策への第一歩です。
まずは自分のサイトにどのAIクローラーが来ているか確認してみましょう。対策はそこから始まります。
バクヤスAI 記事代行では、
高品質な記事を圧倒的なコストパフォーマンスでご提供!

AIクローラーによる影響と課題
サーバー負荷の増大
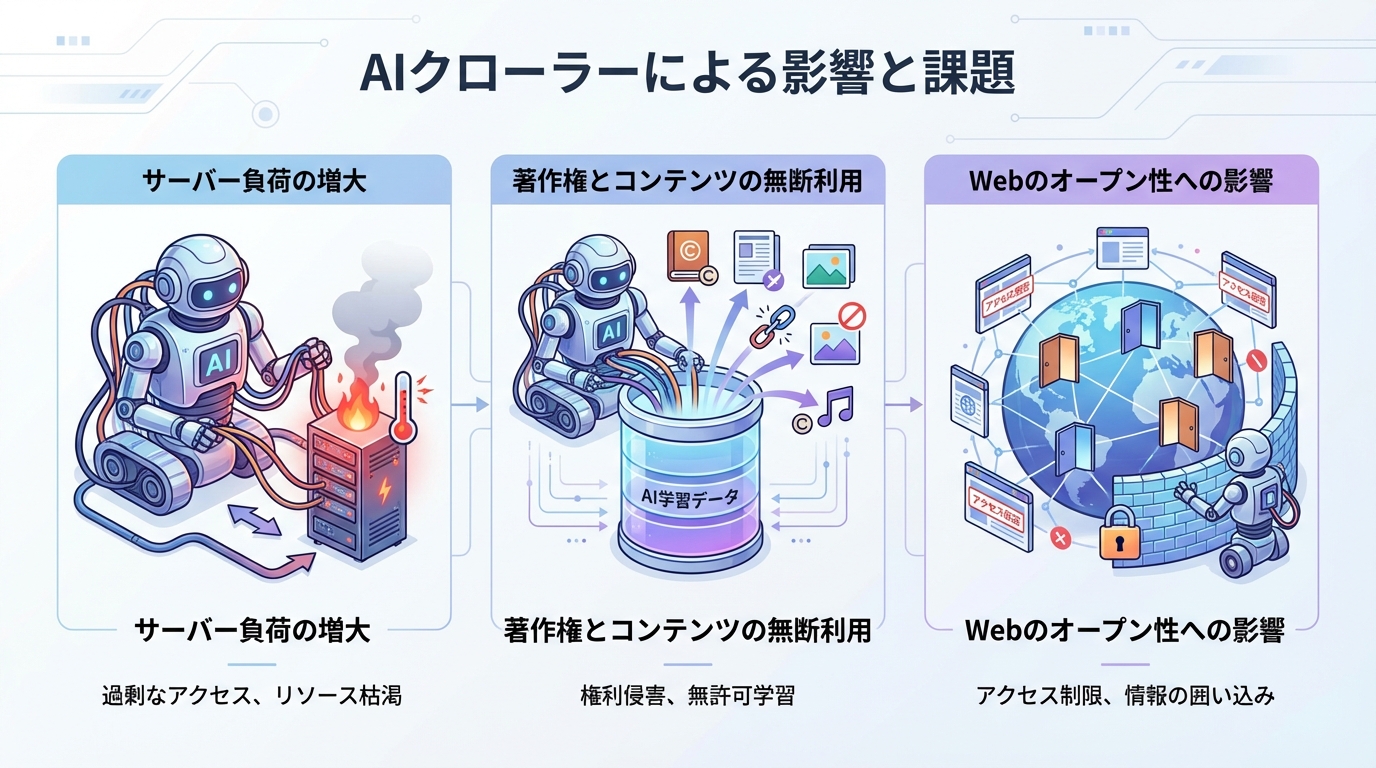
AIクローラーは短時間に大量のページへアクセスするケースがあり、サーバーに対して過度な負荷を与える可能性があります。特に小規模なサイトや共有サーバーを利用している場合、AIクローラーによるアクセスが集中するとページの表示速度低下やサーバーダウンを引き起こすことがあります。
検索エンジンのクローラーは一般的にクロール速度を調整する仕組みを持っていますが、AIクローラーのなかにはそうした配慮が十分でないものもあると指摘されています。サーバー負荷の監視を行い、異常なアクセスパターンがないかを日常的にチェックすることが大切です。
著作権とコンテンツの無断利用
AIクローラーによるデータ収集は、著作権の観点からも議論が続いています。サイト上に公開されたテキストや画像がAIの学習データとして利用された場合、元のコンテンツ作成者の許諾なく使われることになります。
AIクローラーによるコンテンツの収集が著作権法上どのように扱われるかは各国で議論が進んでおり、現時点では明確な統一見解が出ていない状況です。サイト運営者としては、法的な動向を注視しつつ、自衛のためにブロック設定を検討する姿勢が求められます。
Webのオープン性への影響
AIクローラーへの対策として多くのサイトがアクセスをブロックするようになると、Web全体のオープン性が低下する可能性も指摘されています。参考情報によれば、AIクローラーの急増に伴い、サイト運営者がクローラーを広範にブロックする動きが加速しており、結果としてWebがより閉鎖的になるリスクがあるとされています。
AIクローラーをブロックすることでサイトを守れる一方で、情報の流通が妨げられるというジレンマが存在します。サイト運営者は、自サイトのコンテンツ保護とWebのオープン性のバランスを意識した判断が求められるでしょう。
以下は、AIクローラーがサイトに与える主な影響をまとめた表です。
| 影響の種類 | 具体的な内容 | リスクの度合い |
|---|---|---|
| サーバー負荷 | 大量アクセスによる速度低下・ダウン | 高い(小規模サイトほど影響大) |
| コンテンツの無断利用 | AI学習データとして許諾なく使用される | 中〜高い |
| SEOへの間接的影響 | サーバー負荷増によるインデックス遅延の可能性 | 中程度 |
| Webのオープン性低下 | 過度なブロックによる情報流通の停滞 | 長期的リスク |
上記のように、AIクローラーの影響は技術的な側面だけでなく、法的・社会的な側面にも及んでいます。対策を検討する際は、これらの多角的な視点を踏まえることが重要です。
AIクローラーの影響はサーバー負荷から著作権まで多方面に及ぶため、総合的に対策を考えていくことが大事です。
バクヤスAI 記事代行では、高品質な記事を圧倒的なコストパフォーマンスでご提供!
バクヤスAI 記事代行では、SEOの専門知識と豊富な実績を持つ専任担当者が、キーワード選定からAIを活用した記事作成、人の目による品質チェック、効果測定までワンストップでご支援いたします。
ご興味のある方は、ぜひ資料をダウンロードして詳細をご確認ください。
サービス導入事例

株式会社ヤマダデンキ 様
生成AIの活用により、以前よりも幅広いキーワードで、迅速にコンテンツ作成をすることが可能になりました。
親身になって相談に乗ってくれるTechSuiteさんにより、とても助かっております。
▶バクヤスAI 記事代行導入事例を見る

AIクローラーのブロック方法
AIクローラーへの対策として、サイト運営者が実践できる具体的なブロック方法がいくつか存在します。ここでは、代表的な方法を手順とともに解説します。自サイトの環境やニーズに合わせて、適切な方法を選択してください。
robots.txtによる制御
robots.txtはWebサイトのルートディレクトリに設置するテキストファイルで、クローラーに対してアクセスの可否を指示する最も基本的な方法です。AIクローラーをブロックする場合は、以下のような記述を追加します。
たとえば、GPTBotとClaudeBotのアクセスを拒否する場合の記述例は次のとおりです。「User-agent」にクローラー名を指定し、「Disallow」に対象パスを指定します。すべてのページへのアクセスを拒否する場合は「Disallow: /」と記述します。
robots.txtでAIクローラーをブロックする際のチェックポイント
- ブロック対象のAIクローラー名(User-agent)を正確に記述する
- Disallowのパス指定に誤りがないか確認する
- 検索エンジンのクローラー(Googlebotなど)を誤ってブロックしない
- ファイルがルートディレクトリに正しく設置されているか確認する
robots.txtは設定が簡単ですが、あくまでクローラー側が指示を尊重することを前提としています。すべてのAIクローラーが従うとは限らない点には注意が必要です。
メタタグによる制御
HTMLのhead要素内にメタタグを記述する方法でも、AIクローラーに対してページのクロールやインデックスを制御できます。ページ単位で細かく設定したい場合には、メタタグの活用が効果的です。
メタタグを使えばページごとにクロール制御ができるため、特定のコンテンツだけをAIクローラーから保護したい場合に適しています。たとえば、「noai」や「noimageai」といった値を指定することで、AIによるコンテンツ学習を拒否する意思を示すことができます。※ただし、これらのメタタグに対応しているAIクローラーは限定的であり、今後の対応状況を確認する必要があります。
.htaccessによるアクセス制限
Apacheサーバーを利用している場合は、.htaccessファイルを使ってAIクローラーのUser-Agentに基づくアクセス制限を設定することも可能です。この方法では、robots.txtを無視するクローラーに対しても強制的にアクセスを拒否できます。
具体的には、特定のUser-Agent文字列を含むリクエストに対して403(アクセス禁止)レスポンスを返す設定を記述します。.htaccessによる制御はサーバーレベルでアクセスを拒否するため、robots.txtよりも強力な対策として位置づけられます。ただし、設定を誤ると正常なアクセスまでブロックしてしまう可能性があるため、慎重に作業してください。
WAFやCDNの活用
より高度な対策として、WAF(Webアプリケーションファイアウォール)やCDN(コンテンツデリバリーネットワーク)のボット管理機能を活用する方法もあります。これらのサービスでは、AIクローラーを含む不要なボットのアクセスを自動的に検知・ブロックする機能を提供しているケースがあります。
以下に、各ブロック方法の特徴を比較した表を示します。
| ブロック方法 | 設定の難易度 | 強制力 | 細かい制御 |
|---|---|---|---|
| robots.txt | 低い | クローラーの遵守に依存 | ディレクトリ単位 |
| メタタグ | 低い | クローラーの遵守に依存 | ページ単位 |
| .htaccess | 中程度 | 高い(サーバーレベル) | User-Agent単位 |
| WAF・CDN | 中〜高い | 高い | ボット種別単位 |
それぞれの方法にメリット・デメリットがあるため、サイトの規模や技術的な環境に応じて組み合わせて使うことも有効な選択肢です。
AIクローラーのブロック対策を実施する前の確認事項
- アクセスログでAIクローラーの種類とアクセス頻度を把握している
- 検索エンジンのクローラーに影響を与えない設定になっている
- 設定変更後にサイトの正常な表示・動作を確認している
- ブロック対象のクローラーの最新User-Agent情報を確認している
ブロック方法は複数あるので、自サイトの環境に合ったものを選んで組み合わせるのがおすすめです。

AIクローラーへの今後の対策
業界標準の動向
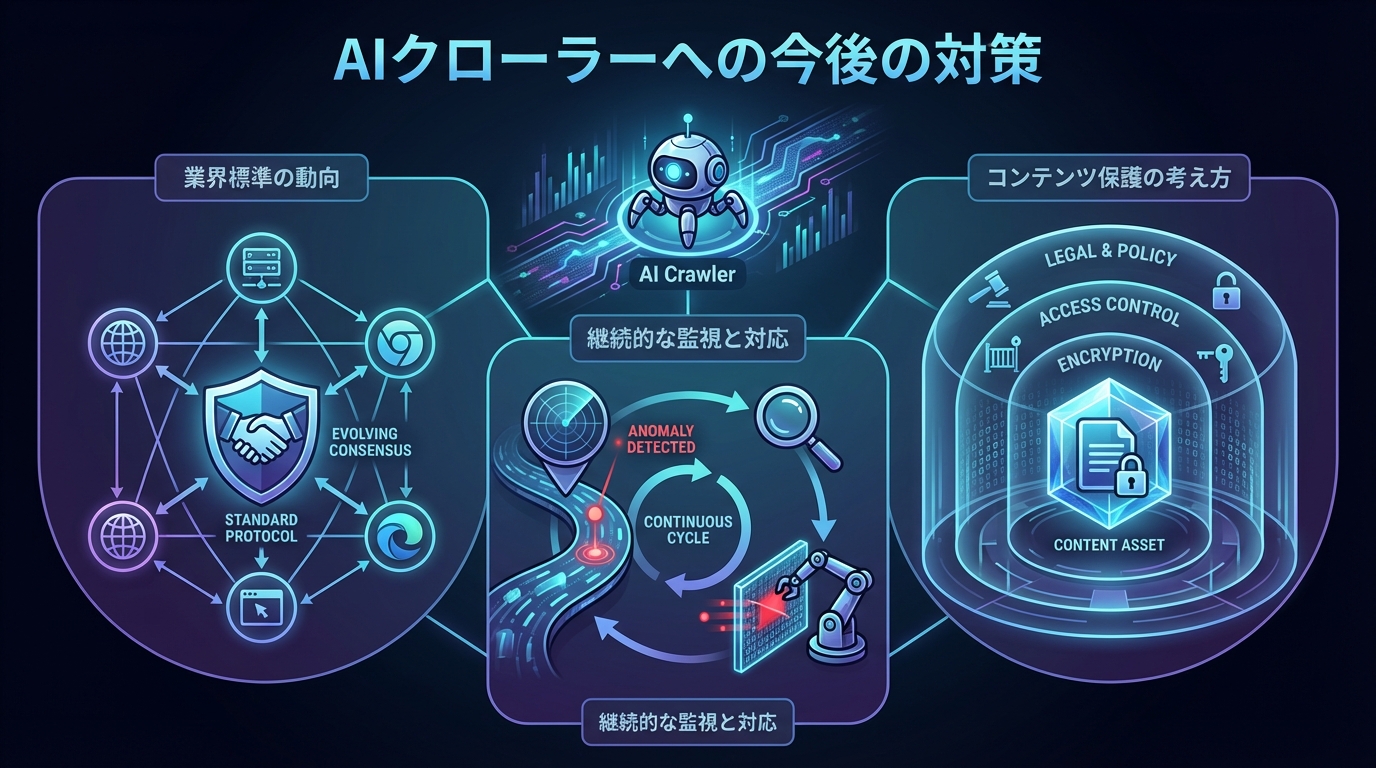
現在、AIクローラーに対する統一的なルールやガイドラインはまだ策定途上にあります。しかし、AI開発元やWeb標準化団体を中心に、クローラーの行動規範や新たな制御手段に関する議論が活発に行われています。
今後、robots.txtに代わる新しい制御プロトコルや、AI学習用のデータ利用に関するライセンスの枠組みが整備される可能性があります。サイト運営者としては、こうした業界動向を継続的にウォッチし、新しい標準に迅速に対応できる体制を整えておくことが望ましいでしょう。
継続的な監視と対応
AIクローラーは新しいものが次々と登場するため、一度設定したブロック対策をそのままにしておくだけでは不十分です。定期的にアクセスログを確認し、新たなAIクローラーの出現や既存クローラーのUser-Agent変更に対応する必要があります。
AIクローラーの対策は「設定して終わり」ではなく、継続的に状況を監視し、必要に応じて設定を更新していくプロセスとして捉えることが大切です。定期チェックのスケジュールを決めておくことで、対応の遅れを防ぐことができます。
AIクローラー対策の定期チェック項目
- アクセスログに新しいAIクローラーのUser-Agentが出現していないか
- robots.txtの設定内容が最新のクローラー情報と一致しているか
- サーバー負荷に異常な増加が見られないか
- AI開発元の公式情報に新しいポリシー変更がないか
コンテンツ保護の考え方
AIクローラーへの対策は、単にブロックするだけでなく、自社コンテンツの価値をどのように守り、活用するかという観点からも考える必要があります。たとえば、一部のコンテンツはAIクローラーに公開しつつ、特に価値の高いコンテンツだけを保護するといった段階的な対応も選択肢の一つです。
また、AI技術の発展はサイト運営者にとって脅威だけではなく、新しい機会を生む面もあります。AI検索やAI要約の結果に自サイトの情報が引用されることで、新たな流入経路が生まれる可能性もあるため、完全なブロックが必ずしも最善策とは限りません。自サイトの方針に合わせた柔軟な判断が求められます。
AIクローラー対策は定期的な見直しが不可欠なので、チェックのルーティンを作っておくとよいでしょう。
よくある質問
- AIクローラーをブロックすると検索順位に影響はありますか?
-
AIクローラー(GPTBot、ClaudeBotなど)をブロックしても、検索エンジンのクローラー(Googlebotなど)とは別物であるため、直接的な検索順位への影響はないと考えられます。ただし、Google-Extendedのように検索エンジンと関連するAIクローラーの場合は、AI検索機能での表示に影響する可能性があります。
- robots.txtでAIクローラーをブロックしても無視されることはありますか?
-
robots.txtはクローラーへの「お願い」にあたるもので、法的な強制力はありません。主要なAI開発元のクローラーは遵守すると表明していますが、すべてのクローラーが従う保証はないため、.htaccessやWAFなどの追加対策を併用することが効果的です。
- すべてのAIクローラーを一括でブロックする方法はありますか?
-
現時点では、すべてのAIクローラーを一括で指定してブロックする標準的な方法は確立されていません。robots.txtに個別のクローラー名を記述するか、.htaccessやWAFでUser-Agentベースの包括的なフィルタリングを行う方法が考えられます。新しいAIクローラーが増え続けているため、定期的な設定の見直しが必要です。

まとめ
AIクローラーは、AI学習用のデータを収集するためにWebサイトを巡回するプログラムであり、従来の検索エンジン向けクローラーとは目的や挙動が異なります。サーバー負荷の増大やコンテンツの無断利用といった課題があり、サイト運営者にとって適切な対策が求められています。
ブロック方法としては、robots.txt、メタタグ、.htaccess、WAF・CDNの活用など複数の選択肢があります。自サイトの環境や目的に合わせてこれらを組み合わせることが効果的です。
AIクローラーをめぐる状況は日々変化しているため、一度設定して終わりではなく、継続的な監視と定期的な見直しを行っていくことが、サイトを長期的に守るための鍵となるでしょう。